

Tutoriel Kafka : les premiers pas avec Apache Kafka

Le logiciel open source Apache Kafka compte parmi les meilleures solutions pour stocker et traiter des flux de données. La plateforme de messagerie et de streaming, disponible sous la licence Apache 2.0, vous séduira par sa tolérance aux erreurs, son extrême adaptabilité et sa remarquable vitesse de lecture et d’écriture. À la base de cette plateforme destinée aux applications Big-Data se trouve une grappe de serveurs (Cluster) qui permet d’enregistrer et de répliquer des données de manière répartie. Il existe quatre interfaces différentes permettant de communiquer avec le cluster au moyen d’un simple protocole TCP.
Dans ce tutorial Kafka, nous vous aidons à faire vos premiers pas avec cette application développée en Scala, à commencer par l’installation de Kafka et du logiciel de synchronisation Apache ZooKeeper.
Conditions pour pouvoir utiliser Apache Kafka
Pour pouvoir utiliser un cluster Kafka performant, vous avez besoin d’un matériel aux performances correspondantes. L’équipe des développeurs recommande l’utilisation de machines équipées d’Intel Xeon avec un Quad-Core et 24 Go de mémoire de travail. Disposer d’une bonne mémoire est impératif pour pouvoir à tout moment assurer la mémoire-tampon des accès en lecture et écriture de toutes les applications actives sur le cluster. Parmi les principaux atouts d’Apache Kafka, il convient de mentionner l’important débit de données, ce qui justifie également le choix de disques durs efficaces et performants. La fondation Apache Software recommande des disques durs de type SATA (8 x 7200 tr/min) et ce pour éviter tout « goulot d’étranglement » dans le flux des données. La qualité des flux dépend donc de la qualité des disques durs.
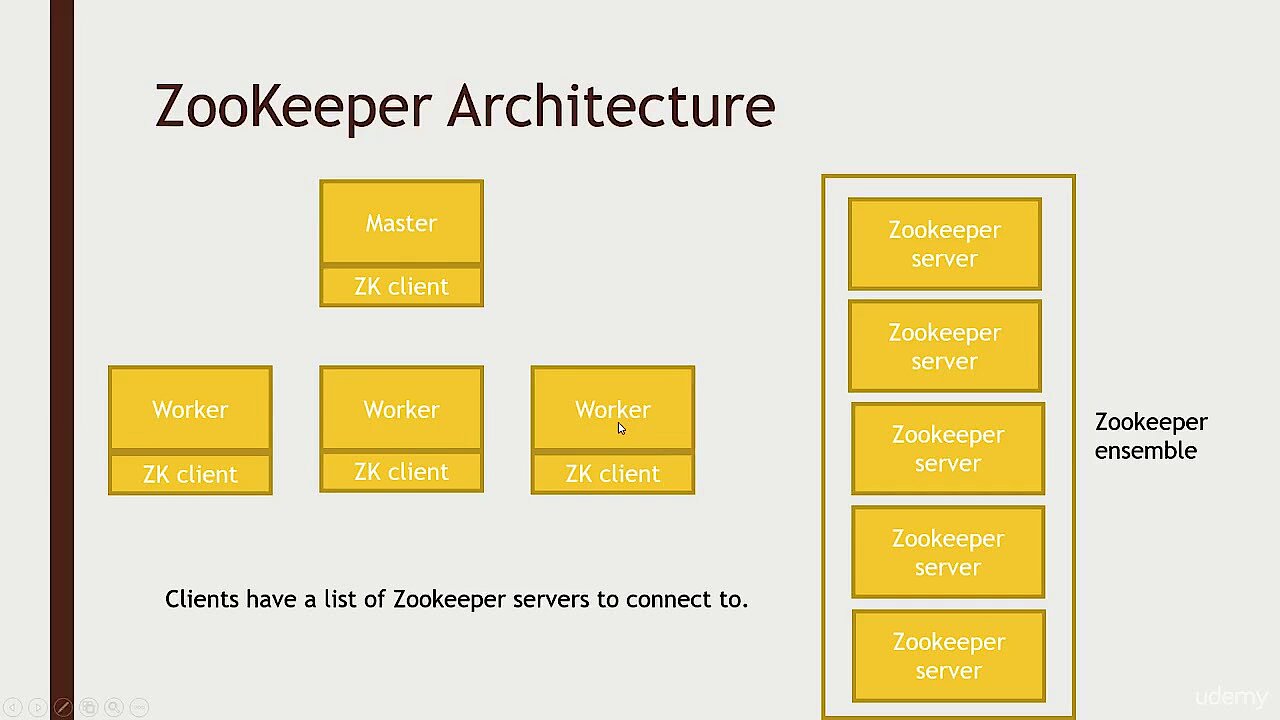
En matière de logiciels, il y a aussi quelques conditions à respecter pour pouvoir utiliser Apache Kafka dans le traitement de flux de données entrants et sortants. Pour le choix du système d’exploitation, nous vous conseillons d’opter pour un système UNIX, comme par exemple Solaris ou une distribution Linux, car les plateformes Windows ne sont que partiellement compatibles. Étant donné que Kafka a été développé sur une base Java, avec le langage de programmation Scala, vous devrez installer une version réactualisée du Kit de développement Java SE (JDK) sur votre machine. Il en va de même pour votre environnement d’exécution Java qui permet d’exécuter des applications Java sur votre ordinateur. Vous aurez nécessairement besoin aussi du service Apache ZooKeeper, un utilitaire qui permet la synchronisation de processus répartis.
 Pour afficher cette vidéo, des cookies de tiers sont nécessaires. Vous pouvez consulter et modifier vos paramètres de cookies ici.
Pour afficher cette vidéo, des cookies de tiers sont nécessaires. Vous pouvez consulter et modifier vos paramètres de cookies ici.
Tutoriel Apache Kafka : comment installer Kafka, ZooKeeper et Java ?
Nous vous avons expliqué précédemment dans ce tutoriel Kafka de quels logiciels vous aviez besoin. Sauf si celui-ci a déjà été installé sur votre ordinateur, nous allons commencer par installer l’environnement d’exécution Java. Plusieurs nouvelles versions des distributions Linux, comme par exemple Ubuntu (que nous allons utiliser à titre d’exemple comme système d’exploitation dans le présent tutorial) disposent avec OpenJDK d’une implémentation JDK gratuite dans le pack de référence officiel. Vous pouvez donc installer le kit de Java tout simplement de cette manière en tapant la commande suivante dans le terminal :
sudo apt-get install openjdk-8-jdkDès que l’installation de Java est terminée, vous continuerez par installer le service de synchronisation Apache ZooKeeper. Celui-ci est également disponible dans le répertoire Ubuntu comme un pack prêt à l’emploi que vous pourrez exécuter au moyen de la ligne de commande suivante :
sudo apt-get install zookeeperdUne commande permet d’ailleurs de vérifier ensuite que le service ZooKeeper a bien été activé :
sudo systemctl status zookeeperSi Apache ZooKeeper fonctionne, le résultat affiché sera le suivant :


Si le service de synchronisation ne fonctionne pas, vous pouvez à tout moment le démarrer à l’aide de la commande suivante :
sudo systemctl start zookeeperPour que ZooKeeper soit automatiquement activé au démarrage de votre ordinateur, vous devez l’enregistrer comme programme par défaut au démarrage :
sudo systemctl enable zookeeperPour finir, vous devez enregistrer un profil d’utilisateur Kafka qui vous sera utile plus tard lorsque vous devrez accéder au serveur. Ouvrez à nouveau le terminal et tapez la commande suivante ;
sudo useradd kafka -mAvec le gestionnaire de mots de passe passwd, assignez à l’utilisateur un mot de passe en tapant la commande suivante, suivie du mot de passe de votre choix :
sudo passwd kafkaL’étape suivante consiste à accorder à l’utilisateur des droits sudo « Kafka » :
sudo adduser kafka sudoÀ tout moment, vous pourrez vous connecter avec le nouveau profil d’utilisateur que vous avez créé :
su – kafkaLe moment est venu de télécharger et d’installer Kafka. Il existe plusieurs emplacements fiables où vous pouvez télécharger des versions anciennes ou plus récentes du logiciel de streaming et de stockage. Vous pouvez aussi télécharger les fichiers d'installation directement à la source, par exemple dans l’espace de téléchargement de la fondation Apache Software. Nous vous recommandons de toujours utiliser une version mise à jour de Kafka. Pour ce faire, ajoutez dans votre terminal une ligne de commande permettant la mise à jour du logiciel. Peut-être faut-il l’ajuster dans certains cas.
wget http://www.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgzComme le fichier téléchargé est un fichier compressé, vous devez le décompresser :
sudo tar xvzf kafka_2.12-2.1.0.tgz --strip 1Grâce au paramètre « --strip 1 » les fichiers décompressés seront directement extraits et enregistrés dans le dossier « ~/kafka ». Dans le cas contraire, et dans le cas précis de ce tutoriel, Ubuntu enregistrera tous les fichiers dans le répertoire « ~/kafka/kafka_2.12-2.1.0 ». Vous devez avoir précédemment créé avec mkdir un répertoire nommé « kafka » et ensuite accéder à ce répertoire avec la fonction cd kafka.
Apache Kafka : tutoriel pour paramétrer le système de streaming et de messagerie
Après avoir installé Apache Kafka, l’environnement d’exécution Java et ZooKeeper, vous pouvez normalement lancer le service Kafka. Avant de le faire, nous vous conseillons de lancer quelques petites configurations pour que le logiciel soit optimisé en vue des tâches qui vont lui être assignées.
Valider la suppression des topics
Dans sa configuration par défaut, Kafka ne permet pas de supprimer des topics, c’est à dire des messages organisés en catégorie dans un cluster Kafka. Cette fonction peut cependant être activée au moyen du fichier de configuration de Kafka, le fichier server.properties. Ce fichier qui se trouve dans le dossier « Config » peut être ouvert dans l’éditeur de texte nano au moyen de la ligne de commande suivante :
sudo nano ~/kafka/config/server.propertiesTout en bas de ce fichier de configuration, insérez une nouvelle ligne pour permettre la suppression de topics Kafka.
delete.topic.enable=true

N’oubliez pas d’enregistrer l’ajout de cette nouvelle ligne dans le fichier de configuration de Kafka, avant de quitter l’éditeur de texte nano !
Ajouter les fichiers .service pour ZooKeeper et Kafka
La prochaine étape de ce tutoriel Kakfa consiste à créer des fichiers d’unité pour ZooKeeper et Kafka, des fichiers qui permettent de lancer des actions courantes de ces deux services, de les arrêter ou de les relancer, en fonction d’autres services Linux. Il est donc nécessaire, et ce pour les deux applications, de créer et de paramétrer des fichiers .service pour le gestionnaire de session.
Voici comment créer un fichier ZooKeeper compatible avec le gestionnaire de session Ubuntu systemd
Commencez par créer le fichier pour le service de synchronisation ZooKeeper, en tapant la commande suivante dans le terminal :
sudo nano /etc/systemd/system/zookeeper.serviceCette fonction permet non seulement de créer le fichier, mais de l’ouvrir aussitôt dans l’éditeur nano. Entrez-y les lignes suivantes et enregistrez ensuite le fichier :
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetsystemd comprend ainsi qu’il ne doit pas démarrer ZooKeeper avant que le réseau et le système de fichiers définis dans la partie [Unit] soient prêts. La partie [Service] précise que le gestionnaire de session doit utiliser les fichiers zookeeper-server-start.sh et zookeeper-server-stop.sh pour respectivement démarrer et arrêter ZooKeeper. Un redémarrage automatique est par ailleurs envisagé en cas d’arrêt imprévu du service. La ligne [Install] détermine le démarrage du fichier. Par défaut, la valeur employée en cas d’une utilisation multiple (par exemple avec un serveur) est « multi-user.target ».
Comment créer un fichier Kafka destiné au gestionnaire de session Ubuntu
Le fichier .service pour Apache Kafka est créé avec la ligne de commande suivante :
sudo nano /etc/systemd/system/kafka.serviceCopiez ensuite le contenu suivant dans le nouveau fichier que vous avez précédemment ouvert avec l’éditeur nano :
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties > /home/kafka/kafka/kafka.log 2>&1'
ExecStop=/home/kafka/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetDans le champ [Unit] de ce fichier, on précise la dépendance des services Kafka par rapport à ZooKeeper. Cela permet de s’assurer que le service de synchronisation démarre bien dès que le fichier kafka.service est exécuté. La ligne [Service] renferme les scripts Shell kafka-server-start.sh et kafka-server-stop.sh qui déterminent respectivement le démarrage et l’arrêt du serveur Kafka. On y trouve également les informations qui concernent le redémarrage automatique en cas de perte de connexion, ainsi que les données concernant les systèmes à utilisateurs multiples.


Kafka : premier démarrage et création d’un premier enregistrement d’auto-lancement
Après avoir enregistré les données du gestionnaire de session pour Kafka et ZooKeeper, vous pouvez lancer Kafka de la manière suivante :
sudo systemctl start kafkaLe programme systemd utilise par défaut un protocole ou journal centralisé, dans lequel sont enregistrés automatiquement tous les messages de type log. Cela vous permet de vérifier au besoin que le serveur Kafka a bien démarré comme vous le souhaitiez.
sudo journalctl -u kafkaLe résultat doit être approximativement le suivant :


Si le démarrage manuel d’Apache Kafka fonctionne, vous devez encore activer le lancement automatique dans le cadre d’un boot système.
sudo systemctl enable kafkaTutoriel Apache Kafka : les premiers pas avec Apache Kafka
Pour tester Apache Kafka à ce niveau de progression du tutoriel, vous pouvez éditer un message au moyen de la plateforme de messagerie. Pour ce faire, vous avez besoin d’un Producer (producteur) et d’un Consumer (consommateur), c’est à dire une instance qui permette la rédaction et la publication de données sous forme de topics, ainsi qu’une instance capable de lire un topic. Commencez par créer le topic que nous appellerons TutorialTopic. Comme il s’agit d’un simple test, il ne contiendra qu’une seule partition et une seule réplique :
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic TutorialTopicDans un deuxième temps, vous allez créer un Producer qui ajoutera au topic que vous venez de créer un premier message : « Coucou tout le monde ! » Pour ce faire, vous utiliserez le script Shell kafka-console-producer.sh qui répond au nom de l’ordinateur et au port du serveur (dans l’exemple : chemin par défaut Kafka) ainsi qu’au nom du topic :
echo "Coucou tout le monde !" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TutorialTopic > /dev/nullAvec le script kafka-console-consumer.sh, créez ensuite un consommateur Kafka qui traite les messages de TutorialTopic et qui les fait suivre. Encore une fois, les arguments nécessaires seront le nom de l’ordinateur, le port du serveur Kafka et le nom du topic. Ajoutez l’argument « --from-beginning » pour que le message « Coucou tout le monde ! » qui avait été publié avant le démarrage du consommateur, puisse effectivement être traité par celui-ci.
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TutorialTopic --from-beginningLe terminal affiche donc le message « Coucou tout le monde ! » tandis que le script continue à « tourner » dans l’attente de nouveaux messages pouvant être publiés dans ce topic test. Ouvrez une autre fenêtre de terminal dans laquelle vous simulez d’autres données de la part du producteur. Vous les verrez alors s’afficher dans le terminal où est exécuté le script du consommateur.

