

Distributed computing : un calcul distribué pour des infrastructures numériques efficaces

Le Distributed computing (en français « calcul distribué ») a su se rendre indispensable dans la vie et le monde du travail numériques. Lorsque vous allez sur Internet pour effectuer une recherche, vous utilisez le Distributed computing. Les architectures de système distribuées sont également présentes dans de nombreux domaines d’activités et fournissent d’innombrables services si elles disposent d’une capacité de calcul et de traitement suffisante. Nous vous expliquons le fonctionnement de ce processus et vous présentons les architectures de système utilisées ainsi que les domaines d’applications. Dans cet article, nous aborderons également les avantages du calcul distribué.
Qu’est-ce que le Distributed computing ?
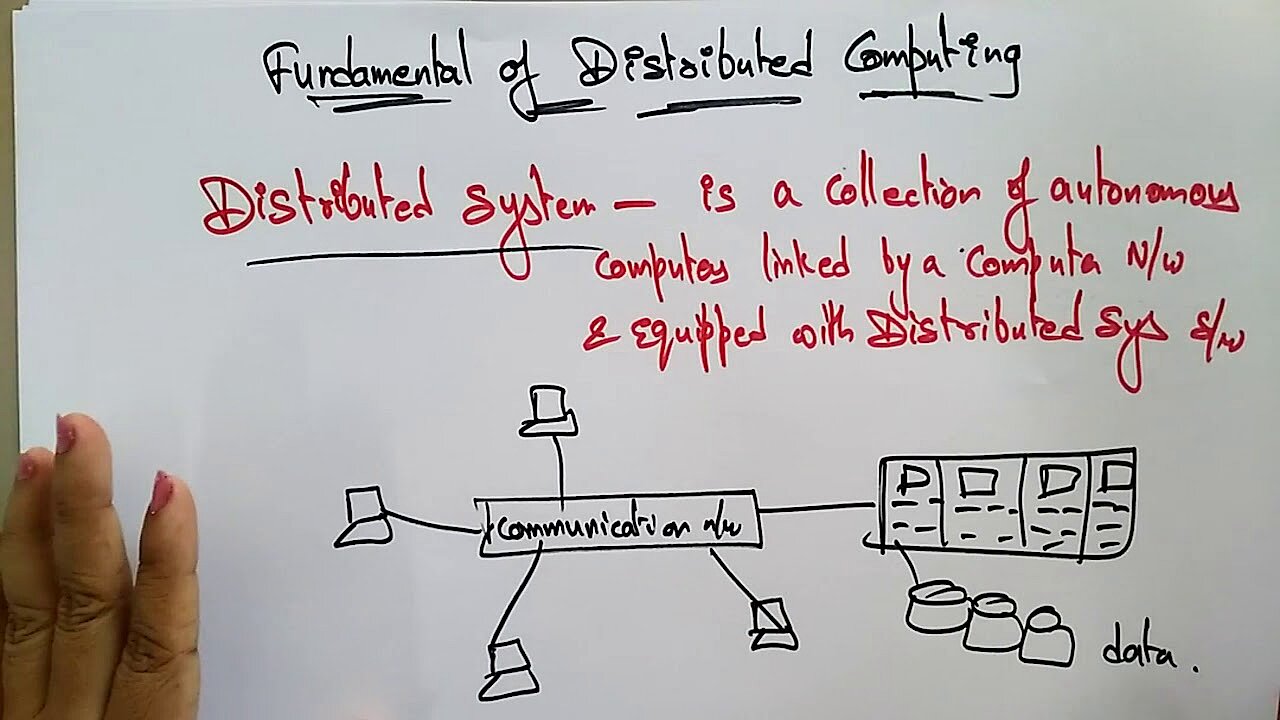
Le terme « Distributed computing » désigne une infrastructure numérique dans laquelle une grappe d’ordinateurs réalise les tâches de calcul entrantes. Malgré une séparation physique, ces ordinateurs autonomes collaborent étroitement dans le cadre d’un processus de partage du travail. Le matériel utilisé est secondaire pour le processus. Outre des ordinateurs et des postes de travail particulièrement performants issus du secteur professionnel, il est également possible d’intégrer des mini-ordinateurs et des PC de bureau de particuliers.
Du fait de leur séparation physique, les matériels distribués ne peuvent pas utiliser une mémoire commune. Les ordinateurs concernés échangent donc les messages et les données (par ex. les résultats de calcul) via un réseau. La communication intermachines est effectuée localement via un Intranet (par ex. dans un centre de calcul) ou globalement via Internet. Le transport des messages est par exemple assuré par des protocoles internet tels que TCP/IP et UDP.
Dans le cadre du principe de transparence, le Distributed computing s’efforce de se présenter comme une unité fonctionnelle vis-à-vis de l’extérieur et de simplifier le plus possible l’utilisation de la technologie. Les utilisateurs démarrant par exemple une recherche de produit dans la base de données d’une boutique en ligne perçoivent l’expérience d’achat comme un processus uniforme et n’ont pas à se préoccuper de l’architecture modulaire de l’infrastructure utilisée.
Finalement, le Distributed computing est la combinaison d’une répartition des tâches et d’une interaction coordonnée. L’objectif est de concevoir une gestion des tâches aussi efficace que possible et de trouver des solutions pratiques et flexibles.
Comment fonctionne le Distributed computing ?
Dans le Distributed computing, le point de départ d’un calcul est une stratégie de résolution des problèmes particulière. Chaque problème individuel est divisé en sous-parties et chaque sous-partie est traitée par une unité de calcul. La mise en œuvre opérationnelle est assurée par des applications distribuées (Distributed applications) exécutées sur toutes les machines de la grappe d’ordinateurs.
Les applications distribuées utilisent souvent une architecture client-serveur. Le client et le serveur se divisent le travail et couvrent certaines fonctions d’application avec les logiciels installés sur le client ou le serveur. Une recherche de produit selon le schéma suivant : Le client agit comme une instance de saisie et une interface utilisateur qui reçoit la requête de l’utilisateur et est conditionnée de façon à pouvoir la transmettre au serveur. Le serveur distant assure ensuite la partie principale de la fonctionnalité de recherche et recherche dans une base de données. Le résultat de cette recherche est conditionné côté serveur afin d’être renvoyé au client et lui est communiqué via le réseau. À la fin du processus, le résultat est affiché sur l’écran de l’utilisateur.
Les processus distribués intègrent souvent des services de middleware (intergiciel). En sa qualité de couche logicielle spécifique, le middleware définit le modèle d’interaction (logique) entre les partenaires et assure la médiation ainsi qu’une intégration optimale dans le système distribué. Des interfaces et des services comblant les vides entre les différentes applications ainsi que permettant et surveillant la communication (par exemple par des contrôleurs de communication) sont ainsi mis à disposition. Pour un déroulement opérationnel, le middleware met par exemple à disposition une procédure éprouvée de communication interprocessus entre plusieurs appareils à l’aide du Remote Procedure Call (RPC). Cette procédure est notamment utilisée fréquemment dans les architectures client-serveur pour les recherches de produit réalisées en interrogeant une base de données.
Cette fonction d’intégration œuvrant en faveur du principe de transparence peut également être perçue comme une tâche de traduction. Les systèmes d’application et les plates-formes techniquement hétérogènes – qui n’ont pas, en temps normal, la capacité de communiquer ensemble – parlent ainsi une même langue et peuvent collaborer de façon productive grâce à un middleware. Outre l’interaction multi-appareils et multiplateformes, le middleware prend également en charge d’autres tâches comme la gestion des données. Il gère aussi l’accès des applications partagées aux fonctions et processus des systèmes d’exploitation disponibles localement sur les ordinateurs connectés.


 Pour afficher cette vidéo, des cookies de tiers sont nécessaires. Vous pouvez consulter et modifier vos paramètres de cookies ici.
Pour afficher cette vidéo, des cookies de tiers sont nécessaires. Vous pouvez consulter et modifier vos paramètres de cookies ici.
Quels types de Distributed computing existe-t-il ?
Le Distributed computing est un phénomène aux multiples facettes avec des infrastructures en partie très différentes. Il est donc difficile de cerner toutes les variantes de Distributed computing. Cependant, on attribue le plus souvent trois sous-secteurs à ce sous-domaine de l’informatique :
- le cloud computing
- le grid computing
- le cluster computing
Dans le cloud computing, le calcul distribué est utilisé afin de mettre des infrastructures et des plates-formes rentables et très évolutives à disposition des clients. Les fournisseurs de cloud mettent généralement à disposition leurs capacités sous la forme de services hébergés accessibles via Internet. En pratique, différents modèles de services sont parvenus à s’imposer :
- Software as a Service (SaaS) : dans le cas d’un SaaS, le client utilise les applications d’un fournisseur de cloud ainsi que l’infrastructure correspondante (par ex. des serveurs, une mémoire en ligne, des capacités de calcul). Les applications sont accessibles sur différents appareils via une « Thin Client Interface » (par exemple une application Web basée sur un navigateur). L’entretien et l’administration de l’infrastructure délocalisée sont assurés par le fournisseur de cloud.
- Platform as a Service (PaaS) : dans le cas d’une PaaS un environnement basé sur le cloud est mis à disposition par exemple pour développer des applications Web. Le client dispose d’un contrôle sur les applications mises à disposition et peut procéder à des réglages spécifiques à l’utilisateur. Le fournisseur de cloud se charge de l’infrastructure technique nécessaire au Distributed computing.
- Infrastructure as a Service (IaaS) : dans le cas d’une IaaS, le fournisseur de cloud met à disposition une infrastructure technique à laquelle les utilisateurs peuvent accéder via des réseaux privés ou publics. L’infrastructure mise à disposition inclut notamment des composants tels que des serveurs, des capacités de calcul et des capacités réseau, des appareils de communication comme un routeur, des switches ou des pare-feu, de l’espace de stockage ainsi que des systèmes pour l’archivage et la sécurisation des données. De son côté, le client dispose d’un contrôle sur les systèmes d’exploitation et les applications mises à disposition.
Du point de vue de la conception, le grid computing ressemble à un superordinateur avec une énorme puissance de calcul. Les tâches de calcul ne sont toutefois pas traitées par une, mais par de nombreuses instances. Dans ce cadre, les serveurs et les PC peuvent réaliser différentes tâches sans dépendre les uns des autres. Pour exécuter ces tâches, le grid computing peut accéder de façon très flexible aux ressources. D’ordinaire, les participants mettent à disposition des capacités de calcul pour un projet global lorsque l’infrastructure technique n’est pas trop chargée.
L’avantage est que cette méthode permet d’utiliser rapidement des systèmes très performants et d’adapter la puissance de calcul si besoin est. Pour augmenter la puissance, il n’est pas nécessaire de se rééquiper avec un superordinateur plus coûteux encore.
Le grid computing permettant de générer un superordinateur virtuel à partir d’une grappe d’ordinateurs distants, il convient parfaitement pour résoudre des problèmes nécessitant une forte puissance de calcul. Ce procédé est souvent utilisé pour des projets ambitieux dans le domaine scientifique ou pour décrypter des codes cryptographiques.
Le cluster computing n’est pas facile à distinguer du cloud computing et du grid computing. Ce terme a toutefois une signification plus générale et fait référence à toutes les formes regroupant des ordinateurs individuels et leurs capacités de calcul en un cluster (en français « grappe »). Il existe par exemple des clusters de serveurs, des clusters dans le Big Data et les environnements cloud, des clusters de bases de données ainsi que des clusters d’applications. Par ailleurs, les grappes d’ordinateurs participent de plus en plus au High performance computing qui permet de résoudre des problèmes de calcul particulièrement exigeants.
Différents types de Distributed computing peuvent également être observés lorsque les architectures de système et les modèles d’interaction d’une infrastructure distribuée sont pris pour base. Du fait de la complexité des architectures de système du Distributed computing, on parle également de Distributed Systems (en français « systèmes distribués »).
Parmi les modèles répandus d’architectures de Distributed computing, on trouve :
- le modèle client-serveur
- le modèle pair-à-pair
- les architectures en couches
- l’architecture orientée service (en anglais service-oriented architecture ou SOA)
Le modèle client-serveur est un modèle d’interaction et de communication simple du Distributed computing. Un serveur reçoit une requête d’un client, réalise les procédures de traitement correspondantes et envoie une réponse (message, données, résultats de calcul) au client.
Une architecture pair-à-pair organise les interactions et la communication du calcul distribué selon des critères décentralisés. Tous les ordinateurs (également appelés nœuds) sont égaux et assurent les mêmes tâches et fonctions au sein du réseau. Chaque ordinateur est donc en mesure d’agir à la fois comme client et comme serveur. La blockchain des cryptomonnaies est un exemple d’architecture pair-à-pair.
Dans une architecture en couches, les différents aspects d’un système logiciel sont répartis sur plusieurs couches (en anglais tier layer) ce qui permet d’augmenter l’efficacité et la flexibilité du Distributed computing. On rencontre souvent cette architecture de système, qui peut comporter deux ou trois couches selon les besoins, dans les applications Web.


Une architecture orientée service (SOA) met l’accent sur les services et est axée sur les besoins individuels et les processus d’une entreprise. Les différents services peuvent ainsi être regroupés pour former un processus commercial sur mesure. Par exemple, le processus global « Commande en ligne » – impliquant les services « Enregistrement de la commande », « Vérification de la solvabilité » et « Envoyer la facture » – est illustré dans un SOA. Les composants techniques (serveurs, bases de données, etc.) servent d’outils mais ne sont pas placés au premier plan. Dans ce concept de Distributed computing, la priorité est accordée à un regroupement, une collaboration et une organisation pertinents des services dans le but d’atteindre un déroulement aussi efficace et fluide que possible pour les processus commerciaux.
Dans une architecture orientée service, on veille tout particulièrement à avoir des interfaces bien définies afin de relier les composants de façon opérationnelle et d’augmenter l’efficacité. La flexibilité du système contribue également à l’efficacité puisque les services peuvent être utilisés de façon variée dans plusieurs contextes et réutilisés dans les processus commerciaux. Les architectures orientées service s’appuyant sur le Distributed computing sont souvent basées sur des services Web. Elles sont par exemple réalisées sur des plates-formes distribuées comme CORBA, MQSeries et J2EE.
Les avantages du Distributed computing
Le calcul distribué présente de nombreux avantages. Les entreprises peuvent développer une infrastructure performante et abordable en utilisant des ordinateurs courants peu coûteux avec des microprocesseurs à la place de superordinateurs extrêmement chers (mainframes). Les grands clusters peuvent même dépasser la performance de supercalculateurs individuels et parvenir à résoudre des tâches complexes et gourmandes en puissance de calcul dans le domaine du High performance computing.
Les architectures du Distributed computing comportent plusieurs composants, parfois redondants. Il est donc plus facile de compenser la panne d’une unité individuelle (fiabilité accrue). Le haut niveau de répartition des tâches permet de délocaliser les processus et de répartir la charge de calcul (répartition de la charge).
De nombreuses solutions du Distributed computing visent davantage de flexibilité augmentant ainsi l’efficacité et la rentabilité. Pour résoudre certains problèmes, il est possible d’intégrer des plates-formes spécialisées comme des serveurs de bases de données. Par exemple, l’utilisation d’architectures SOA dans le secteur commercial permet de mettre en place des solutions individuelles optimisant certains processus commerciaux de façon spécifique. Les fournisseurs peuvent proposer leurs capacités de calcul et des infrastructures dans le monde entier ce qui rend par exemple possible un travail sur le cloud. Une telle possibilité permet de réagir aux besoins des clients avec des offres et des tarifs échelonnés et orientés sur les besoins.
La flexibilité du calcul distribué inclut la possibilité d’utiliser les capacités temporairement inutilisées pour des projets particulièrement ambitieux. Les utilisateurs et les entreprises gagnent également en flexibilité dans l’acquisition du matériel puisqu’ils ne sont pas tenus de s’approvisionner auprès d’un seul fabricant.
Par ailleurs, l’évolutivité est un avantage déterminant. Les entreprises peuvent s’adapter rapidement et à court terme ou adapter progressivement la capacité de calcul nécessaire en cas de croissance organique continue. Si vous souhaitez vous appuyer sur votre propre matériel pour évoluer, le parc de machines peut être continuellement élargi en procédant par des étapes successives abordables.
Malgré de nombreux avantages, le Distributed computing a également certains inconvénients, notamment un effort d’implémentation et de maintenance accru pour les architectures de système complexes. D’autre part, il est nécessaire de gérer les problèmes de timing et de synchronisation entre les instances distribuées. En terme de fiabilité, une approche décentralisée comporte certains avantages par rapport à une instance de traitement unique. Le Distributed computing s’accompagne aussi de problèmes de sécurité, notamment en raison du transport des données via des réseaux publics et de leur vulnérabilité face à un sabotage ou un piratage. En général, les infrastructures distribuées sont par ailleurs davantage sujettes aux erreurs puisqu’elles disposent d’un plus grand nombre d’interfaces et donc de sources d’erreur potentielles au niveau du matériel et du logiciel. Du fait de la complexité des infrastructures, le diagnostic des problèmes et des erreurs est également plus compliqué.
Dans quelles situations le Distributed Computing est-il utilisé ?
Que ce soit dans notre vie privée ou professionnelle, le Distributed computing est aujourd’hui une technologie de base de la numérisation. Sans les architectures client-serveur des systèmes distribués, Internet et les services qui y sont proposés seraient impensables. Le Distributed computing intervient dans toutes les recherches Google lorsque des instances sous-traitantes du monde entier collaborent pour générer un résultat pertinent. Google Maps et Google Earth reposent également sur le Distributed computing pour fournir leurs services.
De plus, les systèmes de messagerie et de conférence, les systèmes de réservation des compagnies aériennes et des chaînes d’hôtels, les bibliothèques et les systèmes de navigation utilisent également les processus et les architectures du calcul distribué. Les processus d’automatisation ainsi que les systèmes de planification, de production et de conception dans le monde du travail sont l’un des domaines d’application privilégiés de cette technologie. D’autre part, les réseaux sociaux, les systèmes mobiles, les banques et les jeux en ligne (par ex. les systèmes multijoueurs) utilisent des systèmes distribués efficaces.
Les plates-formes de e-learning, l’intelligence artificielle et le e-commerce constituent d’autres domaines d’application du calcul distribué. Les achats et les processus de commande dans les boutiques en ligne reposent normalement sur des systèmes distribués. En météorologie, les systèmes de captage et de surveillance utilisés par les scientifiques pour prévoir les catastrophes s’appuient sur les capacités de calcul de systèmes distribués. De nombreuses applications numériques sont aujourd’hui basées sur les bases de données distribuées.
Par le passé, les projets de recherche nécessitant une puissance de calcul importante devaient utiliser des superordinateurs coûteux (par exemple l’ordinateur Cray). Aujourd’hui, ils peuvent être réalisés avec des systèmes distribués à un prix avantageux. De 1999 à 2020, le projet « Volunteer Computing » Seti@home a fait figure de référence dans le domaine du calcul distribué. D’innombrables ordinateurs de particuliers ont analysé des données du radiotélescope d’Arecibo à Porto Rico et ont aidé l’Université de Berkeley dans sa recherche d’une vie extraterrestre.
La particularité de ce projet résidait dans son approche préservant les ressources : le logiciel d’analyse travaillait uniquement pendant des phases au cours desquels les ordinateurs des utilisateurs étaient inoccupés. Après l’analyse des signaux, les résultats étaient renvoyés à la centrale de Berkeley. Des projets comparables ont été lancés dans le monde entier par d’autres universités et instituts.
Les bases du Distributed computing sont expliquées de façon claire dans plusieurs vidéos explicatives de la chaîne YouTube d’Education 4u.